After this documentation was released in July 2003, I was approached
by Prentice Hall and asked to write a book on the Linux VM under the Bruce Peren's Open Book Series.
The book is available and called simply "Understanding The Linux Virtual
Memory Manager". There is a lot of additional material in the book that is
not available here, including details on later 2.4 kernels, introductions
to 2.6, a whole new chapter on the shared memory filesystem, coverage of TLB
management, a lot more code commentary, countless other additions and
clarifications and a CD with lots of cool stuff on it. This material (although
now dated and lacking in comparison to the book) will remain available
although I obviously encourge you to buy the book from your favourite book
store :-) . As the book is under the Bruce Perens Open Book Series, it will
be available 90 days after appearing on the book shelves which means it
is not available right now. When it is available, it will be downloadable
from http://www.phptr.com/perens
so check there for more information.
To be fully clear, this webpage is not the actual book.




Next: 3.4 High Memory
Up: 3. Describing Physical Memory
Previous: 3.2 Zones
Contents
Index
Subsections
3.3 Pages
Every physical page frame in the system has an associated
struct page which is used to keep track of its status. In the
2.2 kernel [#!bovet00!#], this structure resembled it's equivilent in System
V [#!goodheart94!#] but like the other families in UNIX, the structure
changed considerably. It is declared as follows in  linux/mm.h
linux/mm.h :
:
152 typedef struct page {
153 struct list_head list;
154 struct address_space *mapping;
155 unsigned long index;
156 struct page *next_hash;
158 atomic_t count;
159 unsigned long flags;
161 struct list_head lru;
163 struct page **pprev_hash;
164 struct buffer_head * buffers;
175
176 #if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
177 void *virtual;
179 #endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
180 } mem_map_t;
Here is a brief description of each of the fields:
- list Pages may belong to many lists and this field is used as the
list head. For example, pages in a mapping will
be in one of three circular linked links kept by the
address_space. These are clean_pages,
dirty_pages and locked_pages. In the slab
allocator, this field is used to store pointers to the slab and
cache the page is a part of. It is also used to link blocks of
free pages together;
- mapping When files or devices are memory mapped3.3,
their inodes has an associated address_space. This
field will point to this address space if the page belongs to
the file. If the page is anonymous and mapping is
set, the address_space is swapper_space
which manages the swap address space. An anonymous page is one
that is not backed by any file or device, such as one allocated
for malloc();
- index This field has two uses and what it means depends on the state of
the page what it means. If the page is part of a file
mapping, it is the offset within the file. If the page
is part of the swap cache this will be the offset within
the address_space for the swap address space
(swapper_space). Secondly, if a block of pages
is being freed for a particular process, the order (power
of two number of pages being freed) of the block being freed
is stored in index. This is set in the function
__free_pages_ok();
- next_hash Pages that are part of a file mapping are hashed on the inode
and offset. This field links pages together that share the same
hash bucket;
- count The reference count to the page. If it drops to 0, it may be
freed. Any greater and it is in use by one or more processes or
is in use by the kernel like when waiting for IO;
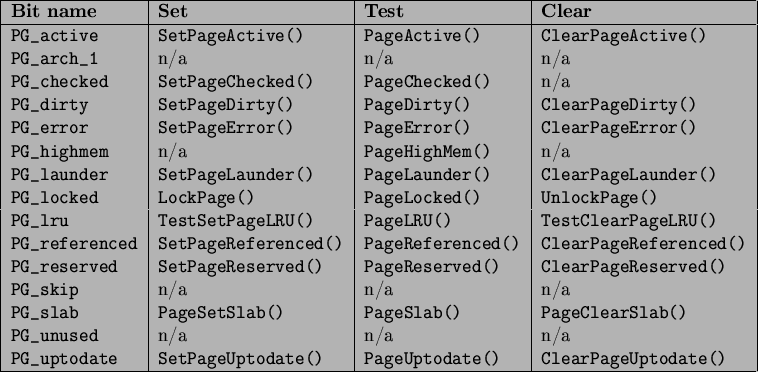
- flags These are flags which describe the status of the page. All of
them are declared in linux/mm.h and are listed
in Table 3.1. There are a number of
macros defined for testing, clearing and setting the bits which
are all listed in Table 3.2;
- lru For the page replacement policy, pages that may be swapped out
will exist on either the active_list or the
inactive_list declared in page_alloc.c. This
is the list head for these LRU lists;
- pprev_hash The complement to next_hash;
- buffers If a page has buffers for a block device associated with it,
this field is used to keep track of the buffer_head. An
anonymous page mapped by a process may also have an associated
buffer_head if it is backed by a swap file. This
is necessary as the page has to be synced with backing storage in
block sized chunks defined by the underlying filesystem;
- virtual Normally only pages from ZONE_ NORMAL are directly
mapped by the kernel. To address pages in ZONE_ HIGHMEM,
kmap() is used to map the page for the kernel
which is described further in Chapter
![[*]](crossref.png) . There are only a fixed number of pages that may be
mapped. When it is mapped, this is its virtual address;
. There are only a fixed number of pages that may be
mapped. When it is mapped, this is its virtual address;
The type mem_map_t is a typedef for struct page
so it can be easily referred to within the mem_map array.
Table 3.1:
Flags Describing Page Status
 |
Table 3.2:
Macros For Testing, Setting and Clearing Page Status Bits
 |
3.3.1 Mapping Pages to Zones
Up until as recently as kernel 2.4.18, a struct page
stored a reference to its zone with page zone which
was later considered wasteful, as even such a small pointer consumes
a lot of memory when thousands of struct pages exist. In
more recent kernels, the zone field has been removed and
instead the top ZONE_SHIFT (8 in the x86) bits of the
pageflags are used to determine the zone a page belongs
to. First a zone_table of zones is set up. It is declared in
linux/page_alloc.c as:
zone which
was later considered wasteful, as even such a small pointer consumes
a lot of memory when thousands of struct pages exist. In
more recent kernels, the zone field has been removed and
instead the top ZONE_SHIFT (8 in the x86) bits of the
pageflags are used to determine the zone a page belongs
to. First a zone_table of zones is set up. It is declared in
linux/page_alloc.c as:
33 zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES];
34 EXPORT_SYMBOL(zone_table);
MAX_NR_ZONES is the maximum number of zones that can be in
a node, i.e. 3. MAX_NR_NODES is the maximum number of nodes
that may exist. This table is treated like a multi-dimensional array. During
free_area_init_core(), all the pages in a node are initialised.
First it sets the value for the table
734 zone_table[nid * MAX_NR_ZONES + j] = zone;
Where nid is the node ID, j is the zone index and zone
is the zone_t struct. For each page, the function
set_page_zone() is called as
788 set_page_zone(page, nid * MAX_NR_ZONES + j);
page is the page to be set. So, clearly the index in the
zone_table is stored in the page.
Footnotes
- ... mapped3.3
- Frequently
abbreviated to mmaped during kernel discussions.
Next: 3.4 High Memory
Up: 3. Describing Physical Memory
Previous: 3.2 Zones
Contents
Index
Mel
2004-02-15